終於到最後一天了,昨天的Spark還沒打完,一樣按照之前的方式,一天寫概念,另一天帶實做。
今天的實作可能沒辦法帶完,不過我還是會盡力。
之後會把之前缺的部分補完,所以前面的文章我會慢慢在更新。
<一樣先發文XD 陸續補文章>
在開始安裝之前,記得要先把Hadoop先裝好,因為Spark有支援CDH4,
所以我就拿之前測試的虛擬機來安裝。
Spark非常貼心,有提供安裝的影片,如果有些細節不了解,可以邊看投影片邊做。
http://spark.incubator.apache.org/screencasts/1-first-steps-with-spark.html
因為Spark是用Scala所撰寫,所以一開始要先安裝Scala
1.安裝scala
一開始可以先看看Spark的說明文件,確定安裝哪一版本的Scala比較適合。

Spark 0.8.0 就搭配Scala 2.9.3服用。
安裝參考網站http://osgux.tumblr.com/post/44635945407/install-scala-2-10-0-in-ubuntu
$ wget http://www.scala-lang.org/files/archive/scala-2.9.3.tgz
$ tar zxf scala-2.9.3.tgz
$ sudo mv scala-2.9.3 /opt/
$ export SCALA_HOME =/opt/scala-2.9.3
$ export PATH=$SCALA_HOME/bin:$PATH
接下來打個scala,就知道有沒有Run成功了。

2.安裝Spark
進入spark解壓縮後的目錄,輸入sbt/sbt assembly 會開始編譯。
PS:這邊我一直編譯有問題,原來有小細節沒有注意到。
https://spark-project.atlassian.net/browse/SPARK-933?jql=text%20~%20%22compile%22
經過一般奮鬥後,終於成功安裝Spark (我換一台乾淨的虛擬機..CentOS)
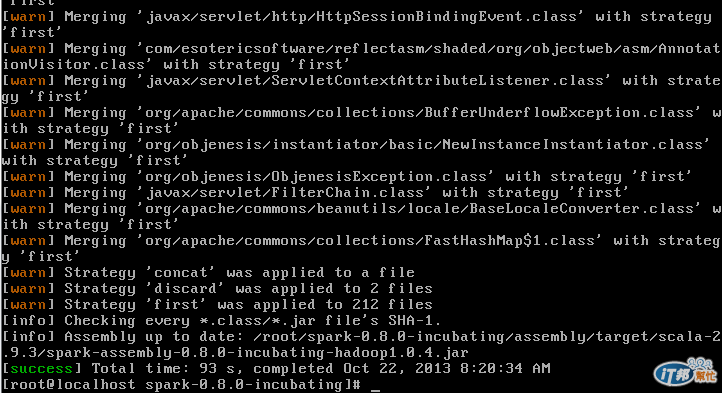
Cloudera的虛擬機,也找到問題了!!

雖然我一直打java -version 版本都是對的,但是javac -version的版本是錯的。
接著要進行設定檔的調整,
邊試邊寫真的是第一手,
比較會有壓力,
而且這個議題目前並不多,
很需要有少見的議題能被展示出來。
也恭禧有撐完。
謝謝啦
撐完還是不夠XD
還是要把文章陸續補完XD



